Estimating software costs remains one of the hardest challenges in engineering management. This paper surveys the major estimation methods, from algorithmic models like COCOMO to agile techniques like Planning Poker, and proposes a new hybrid approach designed for large-scale legacy migration projects.
Introduction
Software Cost Estimation (SCE) stands as a cornerstone challenge in the field of software engineering. This discipline concerns the allocation of resources — encompassing time, people, and capital — required for the completion of software projects.
Part 1: Traditional Algorithmic Models
COCOMO (Constructive Cost Model)
Introduced by Barry Boehm in 1981, COCOMO is perhaps the most widely known algorithmic estimation model. It uses a mathematical formula based on the estimated size of a software project (measured in thousands of lines of code, or KLOC) and a set of cost drivers to estimate effort.
The model comes in three levels of increasing detail:
- Basic COCOMO: A simple, static model that computes effort as a function of program size. While easy to use, it doesn’t account for project-specific factors.
- Intermediate COCOMO: Adds 15 cost driver attributes (such as required reliability, database size, analyst capability) that adjust the base estimate.
- Detailed COCOMO: Further refines the estimate by applying cost drivers at the module level and accounting for phase-specific multipliers.
COCOMO II, released in 2000, updated the model for modern development practices, incorporating object points, function points, and lines of code as size metrics, with adjustments for reuse and software understanding.
Function Point Analysis (FPA)
Developed by Allan Albrecht at IBM in 1979, FPA estimates software size based on functional requirements rather than lines of code. It counts five types of functional components:
- External Inputs (EI): Data entering the system
- External Outputs (EO): Data leaving the system
- External Inquiries (EQ): Interactive queries
- Internal Logical Files (ILF): Data maintained within the system
- External Interface Files (EIF): Data referenced from other systems
Each component is classified by complexity (low, average, high), and the weighted sum produces unadjusted function points. These are then modified by 14 general system characteristics to yield adjusted function points. FPA’s strength lies in its language and technology independence, making it useful for early-stage estimation when implementation details are unknown.
SLIM (Software Lifecycle Management)
Created by Lawrence Putnam in 1978, SLIM is based on the Rayleigh curve model of staffing profiles. It assumes that software development effort follows a predictable distribution over time. The core equation relates software size (in source lines of code) to effort and development time through a technology constant that varies by organization and project type.
SLIM excels at modeling the relationship between schedule compression and effort increase, demonstrating mathematically why crashing a software schedule is exponentially expensive.
Part 2: Expert-Based Methods
Expert Judgment
The most widely used estimation technique in practice, expert judgment relies on the knowledge and experience of seasoned professionals. Experts decompose a project into manageable components and estimate each based on their experience with similar work.
While often accurate for familiar domains, expert judgment suffers from well-documented cognitive biases:
- Anchoring bias: Initial estimates disproportionately influence final figures
- Optimism bias: Systematic underestimation of effort and duration
- Availability bias: Over-reliance on recent or memorable project experiences
Delphi Method
Originally developed by RAND Corporation in the 1950s, the Delphi method structures expert judgment through iterative anonymous estimation rounds. Multiple experts independently estimate, results are shared anonymously, and the process repeats until convergence.
The Wideband Delphi variant, adapted for software estimation, adds group discussion between rounds while maintaining anonymous individual estimates. This approach reduces the influence of dominant personalities while leveraging collective expertise.
Estimation by Analogy
This method estimates new projects by comparing them to completed projects with known costs. The process involves:
- Characterizing the new project across relevant attributes
- Searching a database of completed projects for similar cases
- Adjusting the known costs based on identified differences
The effectiveness depends heavily on the quality and relevance of the historical project database. Organizations with mature data collection practices tend to achieve better results.
Part 3: Machine Learning Approaches
Neural Networks
Researchers have applied various neural network architectures to SCE, training models on historical project data to predict effort. Multi-layer perceptrons, radial basis function networks, and more recently deep learning approaches have shown promising results, sometimes outperforming traditional algorithmic models.
The primary challenge remains data availability: neural networks require substantial training data, and software project datasets are often small, inconsistent, and organization-specific.
Genetic Algorithms
Genetic algorithms have been used to optimize the parameters of estimation models, evolving coefficient values that best fit historical data. They’re particularly useful for calibrating COCOMO-style models to specific organizational contexts.
Ensemble Methods
Recent work has explored combining multiple estimation techniques using machine learning ensemble methods (bagging, boosting, stacking). The intuition is sound: different methods have different strengths, and combining them can reduce individual weaknesses.
Part 4: Agile Estimation Techniques
Story Points
Story points estimate the relative effort of user stories using an abstract scale (often the Fibonacci sequence: 1, 2, 3, 5, 8, 13, 21). Teams calibrate their velocity — the number of story points completed per sprint — to convert relative estimates into calendar time.
Story points work well for sprint planning but struggle with long-term project estimation, particularly for fixed-price contracts or large-scale migrations where stakeholders need upfront cost commitments.
Planning Poker
A consensus-based estimation technique where team members simultaneously reveal their estimates using numbered cards. Discrepancies trigger discussion, helping surface different assumptions and risks. The process combines expert judgment with structured group dynamics, reducing anchoring bias through simultaneous revelation.
Part 5: A New Hybrid Approach
The Problem With Existing Methods
Each method reviewed above has significant limitations for a specific but common scenario: large-scale legacy system migration projects. These projects are characterized by:
- Hundreds or thousands of discrete, semi-homogeneous tasks
- Tasks that vary along two independent dimensions: technical complexity and data volume
- The need for upfront, defensible cost estimates before work begins
- Limited historical data for the specific technology combination involved
COCOMO requires lines of code estimates that don’t exist yet. FPA assumes well-defined functional requirements. Agile methods resist upfront commitment. Expert judgment alone lacks rigor for hundreds of tasks.
Task Discretization
The first innovation is decomposing the project into homogeneous task elements. Rather than estimating the project as a monolith, we identify repeating patterns — each migration task (a screen, a batch process, a service, a report) becomes a discrete estimation unit.
This discretization serves two purposes: it makes individual estimates more tractable, and it creates a statistical population where aggregate behavior becomes predictable even if individual estimates carry uncertainty.
Dual-Factor Qualification
Each task element is qualified along two independent dimensions:
- Complexity (C): Rated 1-5, capturing the technical difficulty of the transformation (business logic complexity, number of dependencies, algorithmic sophistication)
- Volumetry (V): Rated 1-5, capturing the size of the task (number of screens, fields, database tables, lines of code to process)
The effort for each task is computed as:
E = C x V
This yields effort values ranging from 1 to 25, with 13 distinct possible values (since, for example, C=2,V=3 and C=3,V=2 both yield E=6). The two-dimensional qualification captures a reality that single-factor models miss: a task can be simple but large (low C, high V) or small but intricate (high C, low V), and these require fundamentally different resources.
The Abacus System
The critical translation from effort scores to actual days of work is handled by an abacus — a calibrated mapping function. Three mathematical models are proposed:
- Linear model: Days = a x E + b. Assumes proportional scaling. Works for homogeneous task populations.
- Quadratic model: Days = a x E^2 + b x E + c. Captures the super-linear growth of effort with complexity, reflecting the reality that a task twice as complex often takes more than twice as long.
- Exponential model: Days = a x e^(bE). For scenarios where high-complexity, high-volume tasks exhibit explosive effort growth.
The abacus is calibrated using a small sample of fully estimated reference tasks, then applied across the entire population. This is where the method’s power emerges: estimate 20-30 representative tasks carefully, calibrate the model, then apply it to hundreds or thousands.
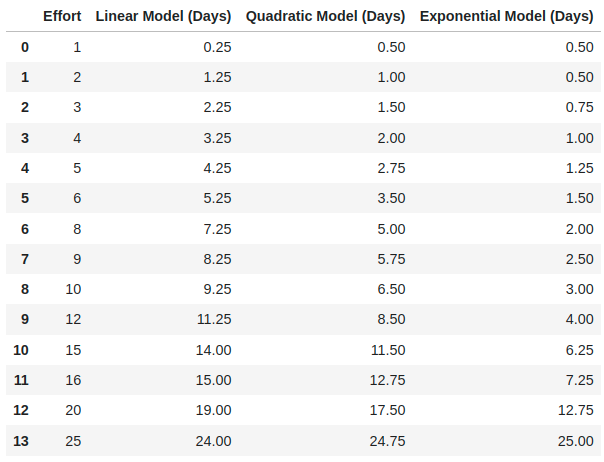 Figure 1. Effort to Days Estimation Models — Data
Figure 1. Effort to Days Estimation Models — Data
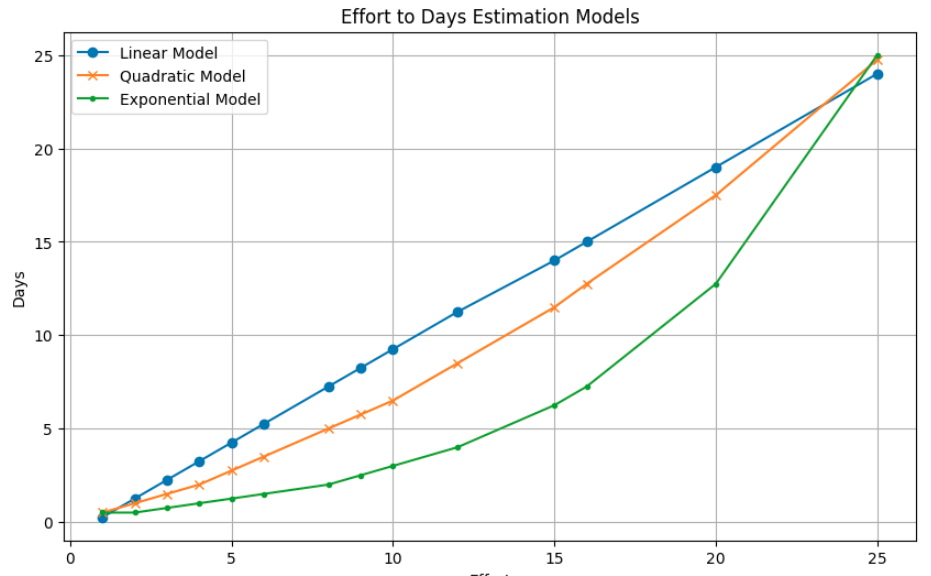 Figure 2. Effort to Days Estimation Models — Graphical representation
Figure 2. Effort to Days Estimation Models — Graphical representation
Three-Phase Process
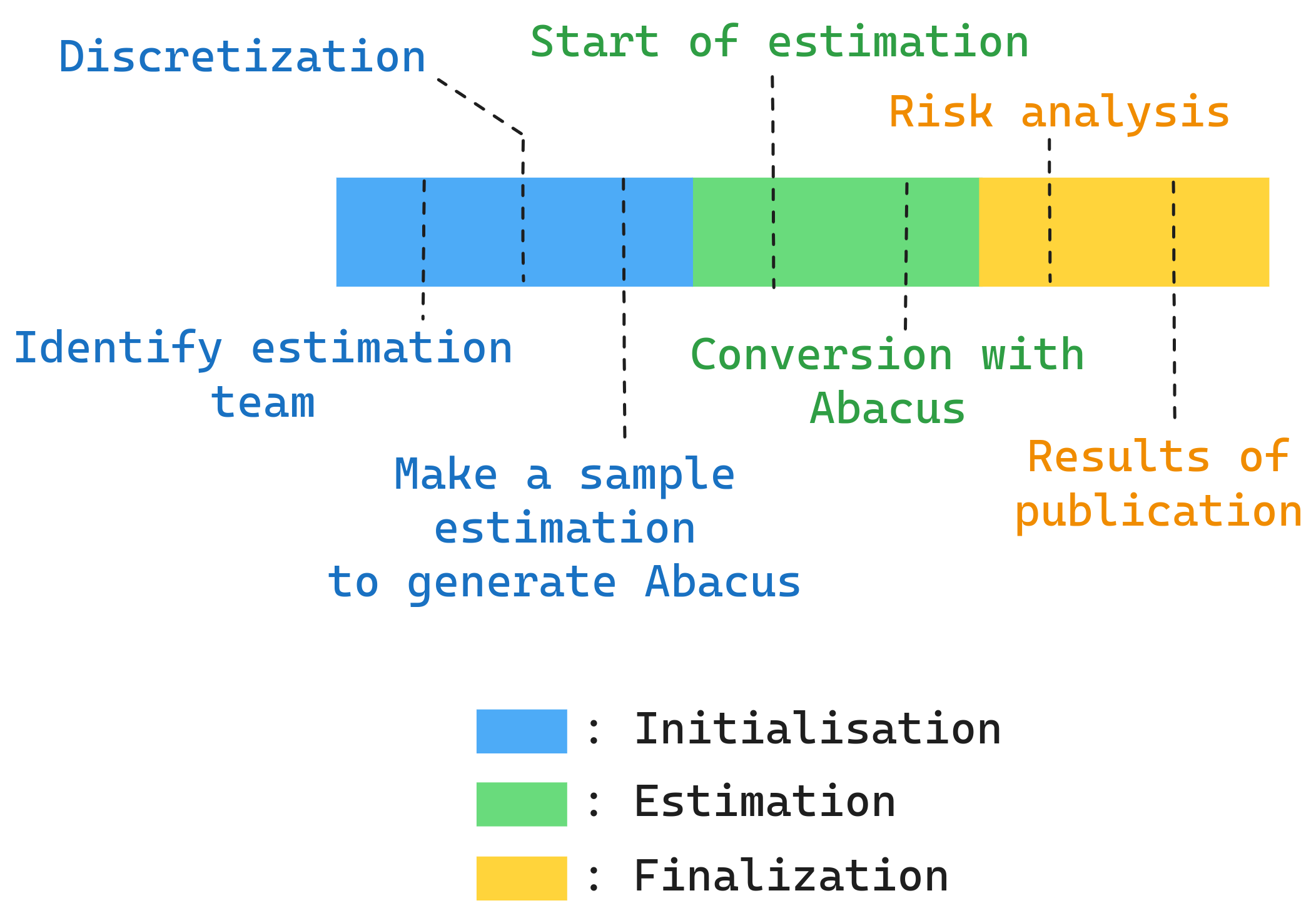 Overview of the three-phase estimation process
Overview of the three-phase estimation process
The method follows three phases:
Phase 1 — Initialization:
- Define the task taxonomy and homogeneous categories
- Establish the complexity and volumetry scales with concrete criteria
- Select and fully estimate reference tasks for calibration
Phase 2 — Estimation:
- Qualify each task element on both dimensions
- Apply the calibrated abacus to compute individual task estimates
- Aggregate to produce the total project estimate
Phase 3 — Finalization:
- Risk analysis using standard deviation across the task population
- Identification of high-effort zones requiring architectural attention
- Sensitivity analysis on the abacus parameters
- Production of confidence intervals and risk-adjusted estimates
Risk Analysis
The method provides built-in risk visibility through statistical analysis of the task population:
- Standard deviation of effort scores reveals estimate dispersion — high dispersion signals risk
- High-effort zone analysis identifies tasks with E > 15 that may require decomposition or alternative approaches
- Distribution analysis can reveal bimodal populations suggesting the task taxonomy needs refinement
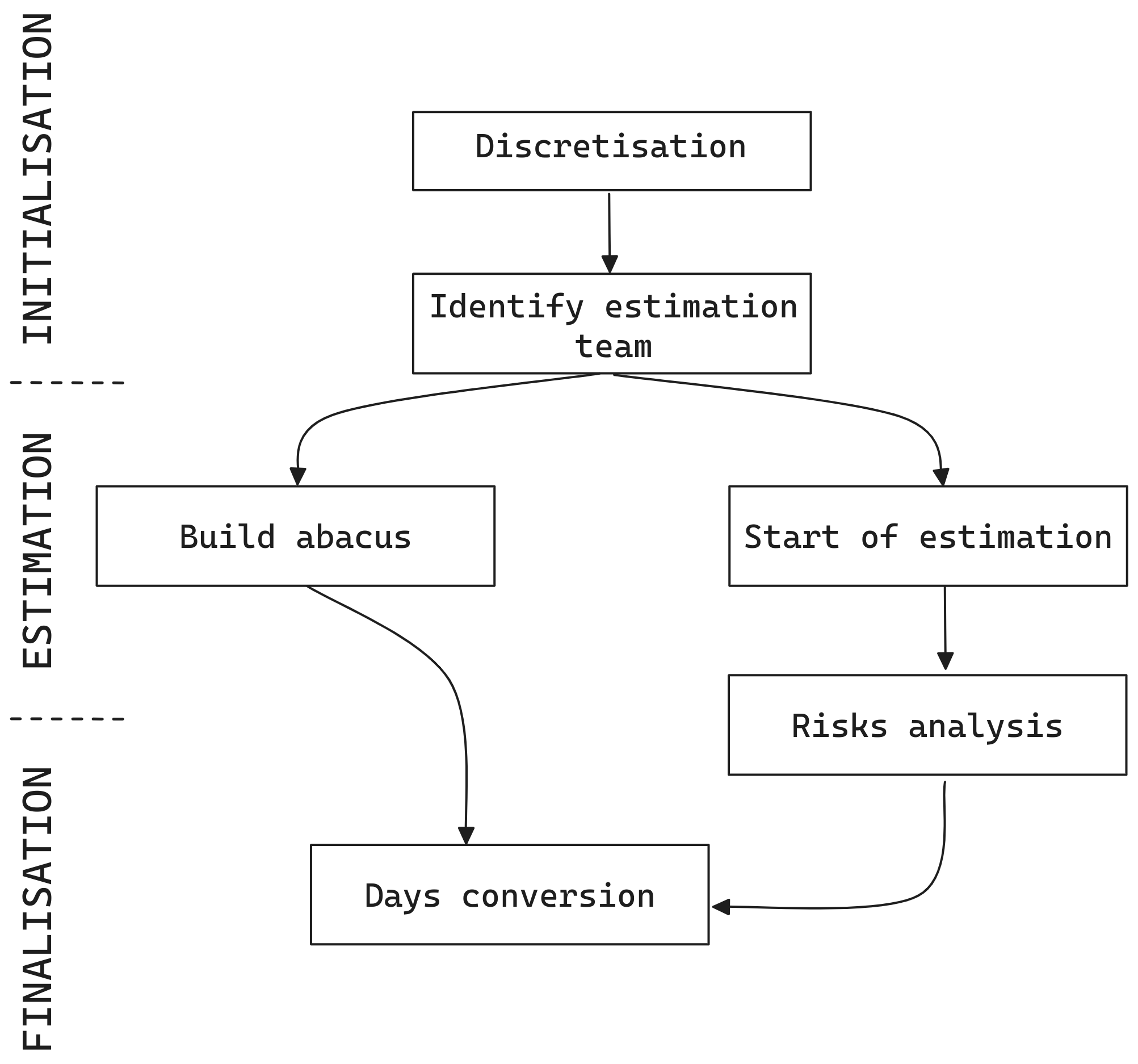 Figure 3. Complete process of the Hybrid-model
Figure 3. Complete process of the Hybrid-model
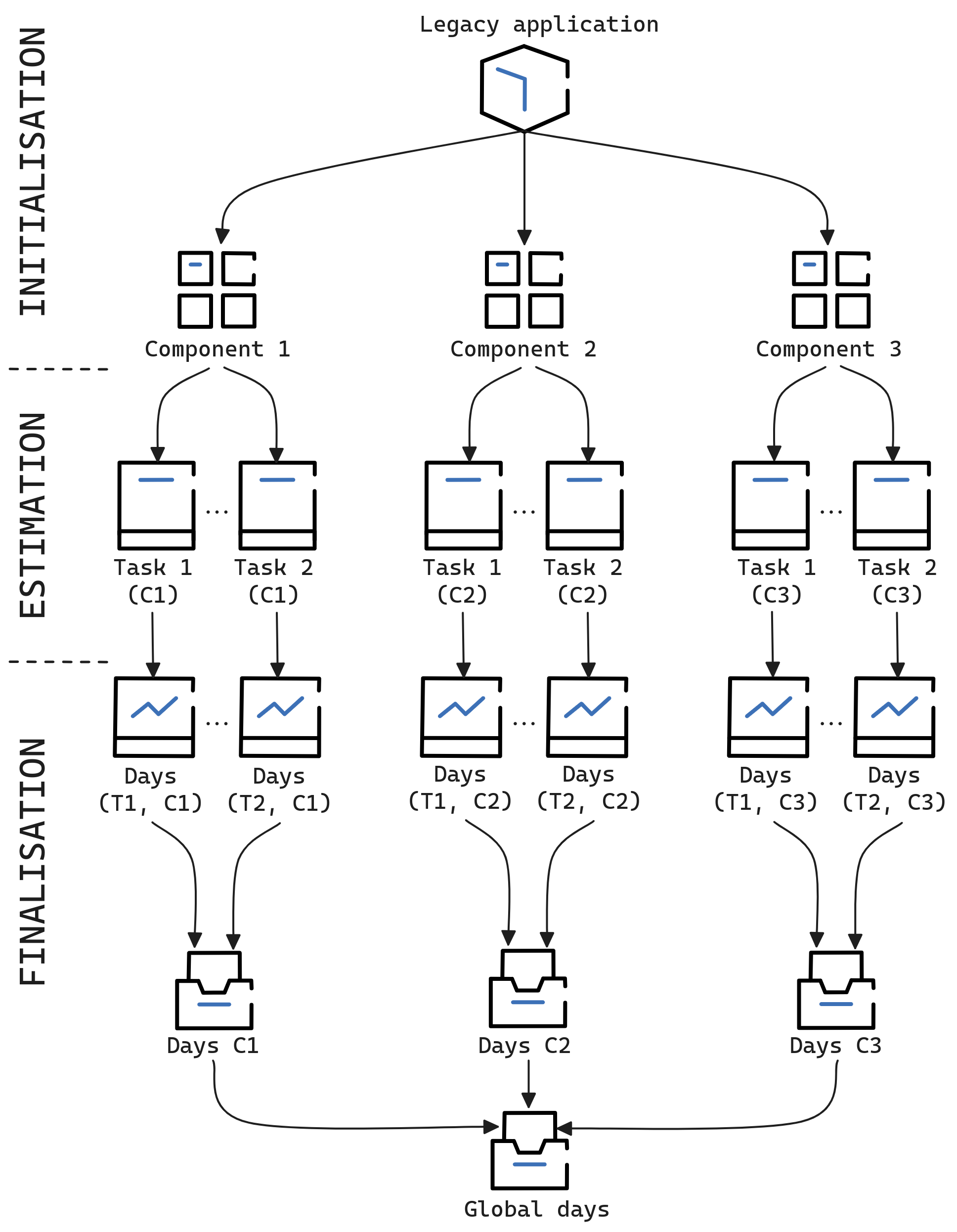 Figure 4. Complete process of the Hybrid-model — Component breakdown
Figure 4. Complete process of the Hybrid-model — Component breakdown
Practical Application
This method has been successfully applied to large legacy migration projects involving hundreds of screens, batches, and services being migrated from legacy platforms to modern architectures. The combination of systematic qualification with calibrated mathematical models provides the rigor that fixed-price engagements demand while remaining practical for teams to apply.
The key insight is that estimation accuracy improves with population size. Individual task estimates may be off by 50%, but across 500 tasks, the aggregate estimate converges to within 10-15% of actual — a level of accuracy that makes the method commercially viable for large-scale fixed-price engagements.
Conclusion
Software cost estimation remains an unsolved problem in the general case, but for specific project profiles — particularly large-scale migrations with repetitive task structures — hybrid approaches that combine structured decomposition with calibrated mathematical models offer a practical path forward.
The dual-factor qualification system captures the multi-dimensional nature of software effort in a way that single-factor models miss. The abacus calibration approach makes the method adaptable to any organization’s context. And the statistical properties of large task populations provide natural risk management.
No estimation method is perfect. But by understanding the strengths and limitations of each approach, and by combining elements thoughtfully, we can make estimates that are defensible, practical, and — most importantly — useful for making real business decisions.
References
- Albrecht, A. J. (1979). “Measuring Application Development Productivity.” IBM Application Development Symposium.
- Boehm, B. W. (1981). “Software Engineering Economics.” Prentice Hall.
- Boehm, B. W. et al. (2000). “Software Cost Estimation with COCOMO II.” Prentice Hall.
- Cohn, M. (2005). “Agile Estimating and Planning.” Prentice Hall.
- Dalkey, N. C. & Helmer, O. (1963). “An Experimental Application of the Delphi Method.” Management Science.
- Grenning, J. (2002). “Planning Poker or How to Avoid Analysis Paralysis while Release Planning.”
- IFPUG (2010). “Function Point Counting Practices Manual, Release 4.3.1.”
- Jorgensen, M. (2004). “A Review of Studies on Expert Estimation of Software Development Effort.” Journal of Systems and Software.
- Jorgensen, M. & Shepperd, M. (2007). “A Systematic Review of Software Development Cost Estimation Studies.” IEEE Transactions on Software Engineering.
- Kemerer, C. F. (1987). “An Empirical Validation of Software Cost Estimation Models.” Communications of the ACM.
- Putnam, L. H. (1978). “A General Empirical Solution to the Macro Software Sizing and Estimating Problem.” IEEE Transactions on Software Engineering.
- Shepperd, M. & Schofield, C. (1997). “Estimating Software Project Effort Using Analogies.” IEEE Transactions on Software Engineering.
- Wen, J. et al. (2012). “Systematic Literature Review of Machine Learning Based Software Development Effort Estimation Models.” Information and Software Technology.
I am CTO at SCUB, a French IT services company, and AI Ambassador for the French Ministry of Economy (“Osez l’IA”). I design production AI systems, contribute to open-source tooling, and write about the intersection of architecture and AI-assisted development.
Originally published on Scub-Lab (Medium).